-
AWS Glue 기초 (S3 Data Catalog 생성)
Cloud 기초/AWS 기초 2023. 9. 6. 03:55(현재 읽고 있는 글은 S3에 대한 기본 정보(https://kh-archive.tistory.com/26) 를 읽은 분들을 대상으로 쓰여졌습니다.)
(S3 bucket에 아래 csv 파일이 저장되어있다고 가정합니다.)

AWS Glue Glue는 AWS에서 제공하는 데이터를 ETL(Extract, Transform, and Load) 서비스입니다.
즉, 데이터의 추출, 변형, 불러오기 등을 도와주는 서비스라는 것이죠.
그 중 Glue가 제공하는 메인 기능 중에 Data Catalog 서비스에 대해서 설명하면
Storage의 Data Meta 정보를 정의하여 쿼리를 날릴 수 있는 형태로 바꿔주는 서비스입니다.
Glue의 뜻만 보면 풀, 접착제 같은 의미입니다. 왜 그런 이름을 붙였을까요?
구체적으로 한번 볼까요?
S3에 Glue를 붙이는 형태를 봅시다.
S3는 주로 비정형 데이터 형태로 데이터를 저장해주는 AWS의 Storage 서비스라고 보면 됩니다.
(간단하게 이해하면 파일을 저장하는 저장소 정도로 이해합시다.)
자세한 내용은 S3에 대한 설명에서 참고하시면 됩니다.
그런데 만약에 csv파일이 많이 S3에 저장되어있는데 열어보니 이런 형식의 파일이라고 생각해봅시다.
May 0.1 0 0 1 1 0 0 0 2 0 0 0 Jun 0.5 2 1 1 0 0 1 1 2 2 0 1 Jul 0.7 5 1 1 2 0 1 3 0 2 2 1 Aug 2.3 6 3 2 4 4 4 7 8 2 2 3 Sep 3.5 6 4 7 4 2 8 5 2 5 2 5 Oct 2.0 8 0 1 3 2 5 1 5 2 3 0 Nov 0.5 3 0 0 1 1 0 1 0 1 0 1 Dec 0.0 1 0 1 0 0 0 0 0 0 0 1 이것만 보면 도대체 뭐하는 숫자인지 알 수도 없고 아무런 쓸모도 없죠. (뭔 숫자인지 알아야 쓰는데 쩝..)
이 상태만 놓고 본다면 그저 데이터를 쌓아두기만 하는 것이지 활용을 할 수 없습니다.
그래서 행과 열이 어떤 데이터를 가리키는지 정의가 필요합니다.
이런 데이터가 무슨 의미로 저장한 것인지 추적을 해보니 사실은 이런 의미로 저장한 것이었다고 합니다.
2005년부터 10년 간 각 연도에 따른 월별 허리케인 발생 빈도 및 평균을 나타낸 표입니다.
Month "Average" "2005" "2006" "2007" "2008" "2009" "2010" "2011" "2012" "2013" "2014" "2015" May 0.1 0 0 1 1 0 0 0 2 0 0 0 Jun 0.5 2 1 1 0 0 1 1 2 2 0 1 Jul 0.7 5 1 1 2 0 1 3 0 2 2 1 Aug 2.3 6 3 2 4 4 4 7 8 2 2 3 Sep 3.5 6 4 7 4 2 8 5 2 5 2 5 Oct 2.0 8 0 1 3 2 5 1 5 2 3 0 Nov 0.5 3 0 0 1 1 0 1 0 1 0 1 Dec 0.0 1 0 1 0 0 0 0 0 0 0 1 하지만 이미 숫자만 달랑 있는 csv 수백 수천개의 파일이 쌓인 상태라면?
저렇게 하나하나 파일을 열어서 Column과 Row를 다 정의해서 다시 업로드할 수 없을 겁니다.
(알바생 100명정도 뽑아서 노가다시키면..)그런데 그 어려운 걸(?) Glue가 도와줍니다!
이제 실제 어떻게 사용하는지 한번 하나하나 살펴보겠습니다.
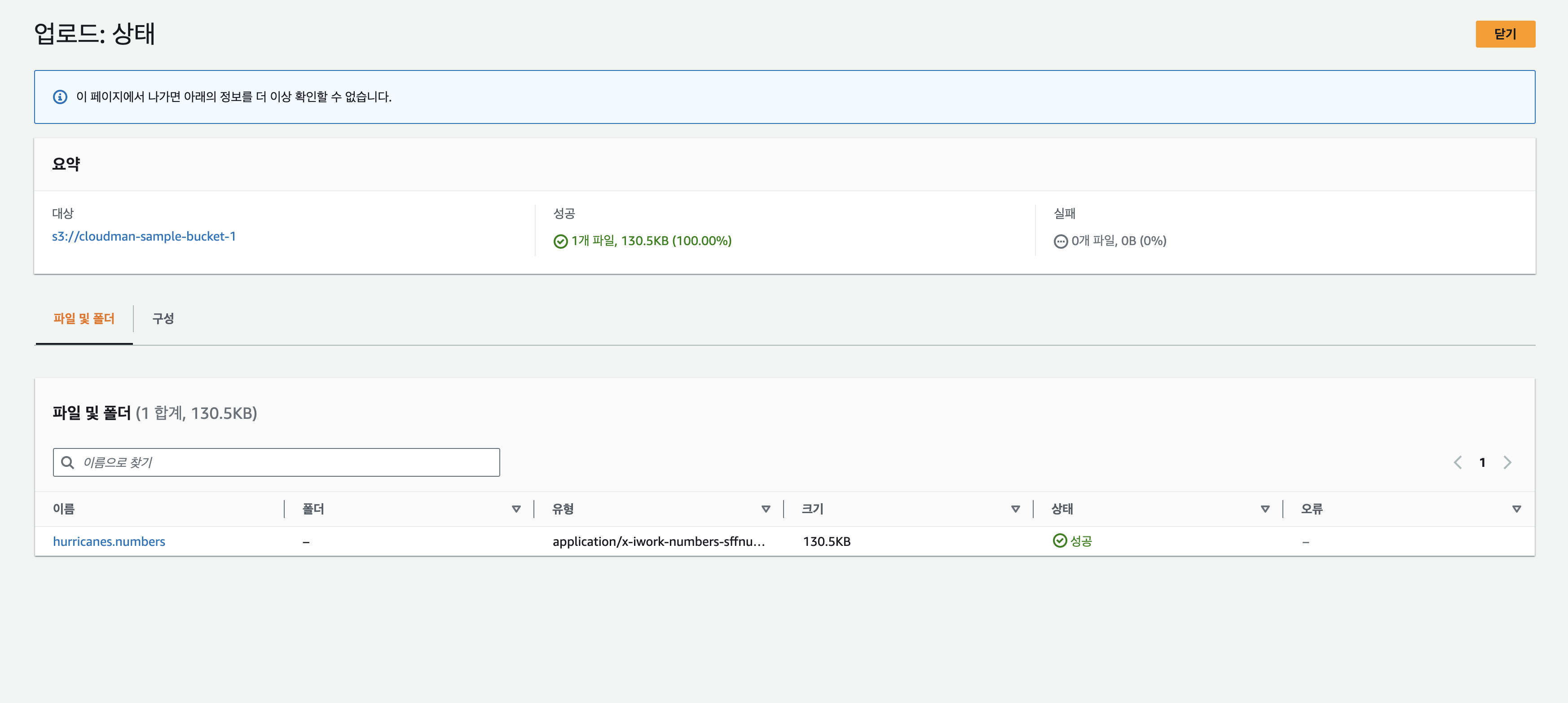
S3 bucket에 저장된 파일 이 파일을 열어보면 위에 보이는 것처럼 몇년부터 몇년까지의 정보인지 칼럼 정보가 없는 파일이 들어가 있습니다.
그리고 RDS처럼 관계형 데이터베이스가 아닌 단순한 스프레트시트 파일이기 때문에 쿼리를 날리는 것이 불가능합니다.
그래서 우리는 여기서 Glue를 붙여서 Athena로 쿼리를 날리는 것까지 해 볼 생각입니다.
AWS Athena는 쿼리 편집기로 나중에 더 자세하게 설명드리겠습니다.
일단 저렇게 세팅을 해놓고 서비스 검색에서 Glue에 들어갑니다. (이 때 새로운 탭으로 들어가면 좋습니다.
그러면 아래와 같은 화면이 보입니다.
Glue 메인 화면 여기서 Data Catalog에 있는 Database를 클릭해봅시다.
Glue Databases RDS를 생각해보면 데이터베이스(DB)가 있고 그 안에 테이블(Table) 형태로 정의된 데이터들이 있죠.
일단 데이터베이스를 추가해봅시다. 오른쪽 상단에 Add database(데이터베이스 추가)를 눌러봅니다.
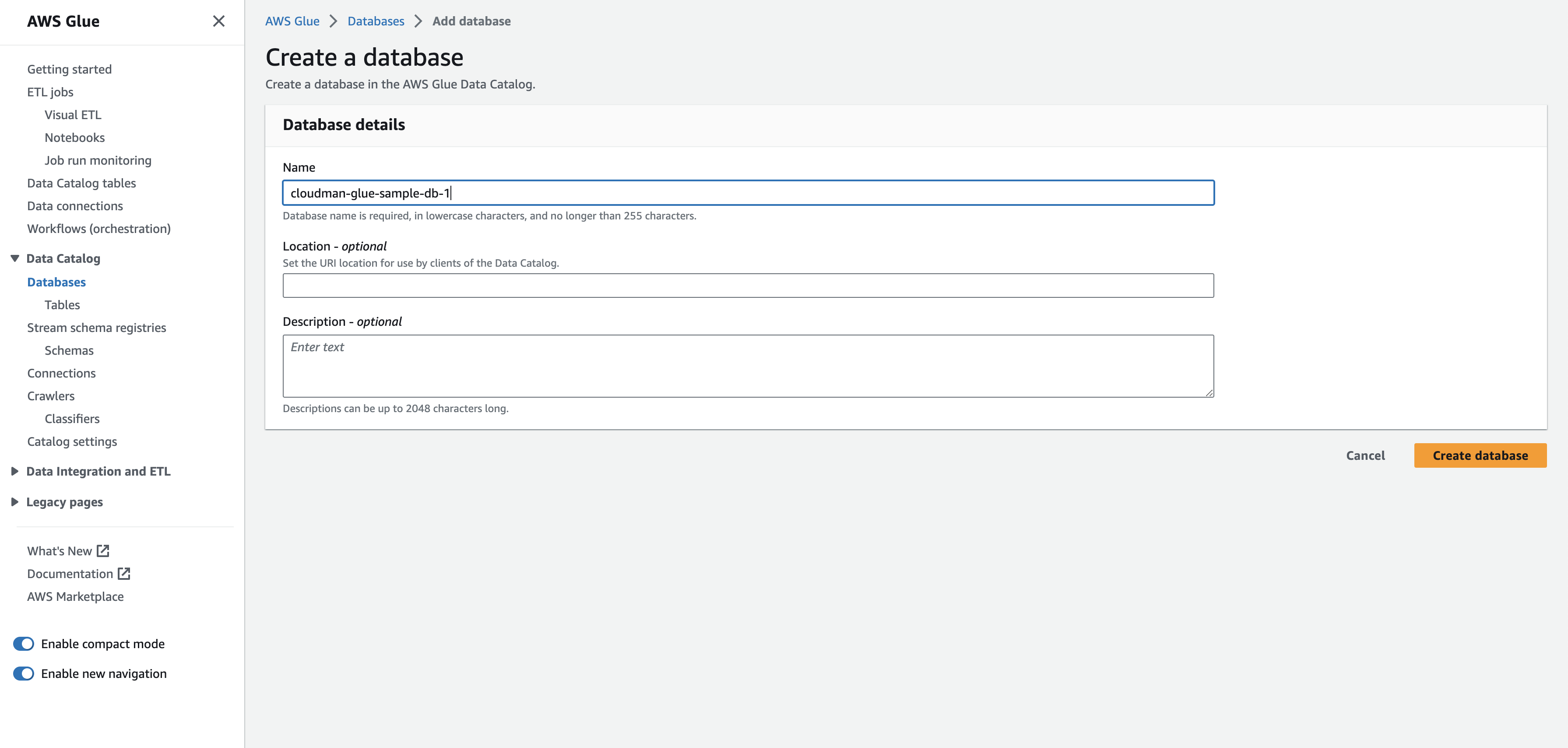
Creat DB in Glue 그러면 이렇게 DB이름과 그밖에 정보를 넣는 화면이 나오는데 이름만 cloudman-glue-sample-db-1로 정하고
Create database를 눌러서 Glue에서 DB를 하나 만들겠습니다.
그러면 이렇게 Glue에서 DB가 만들어졌죠.
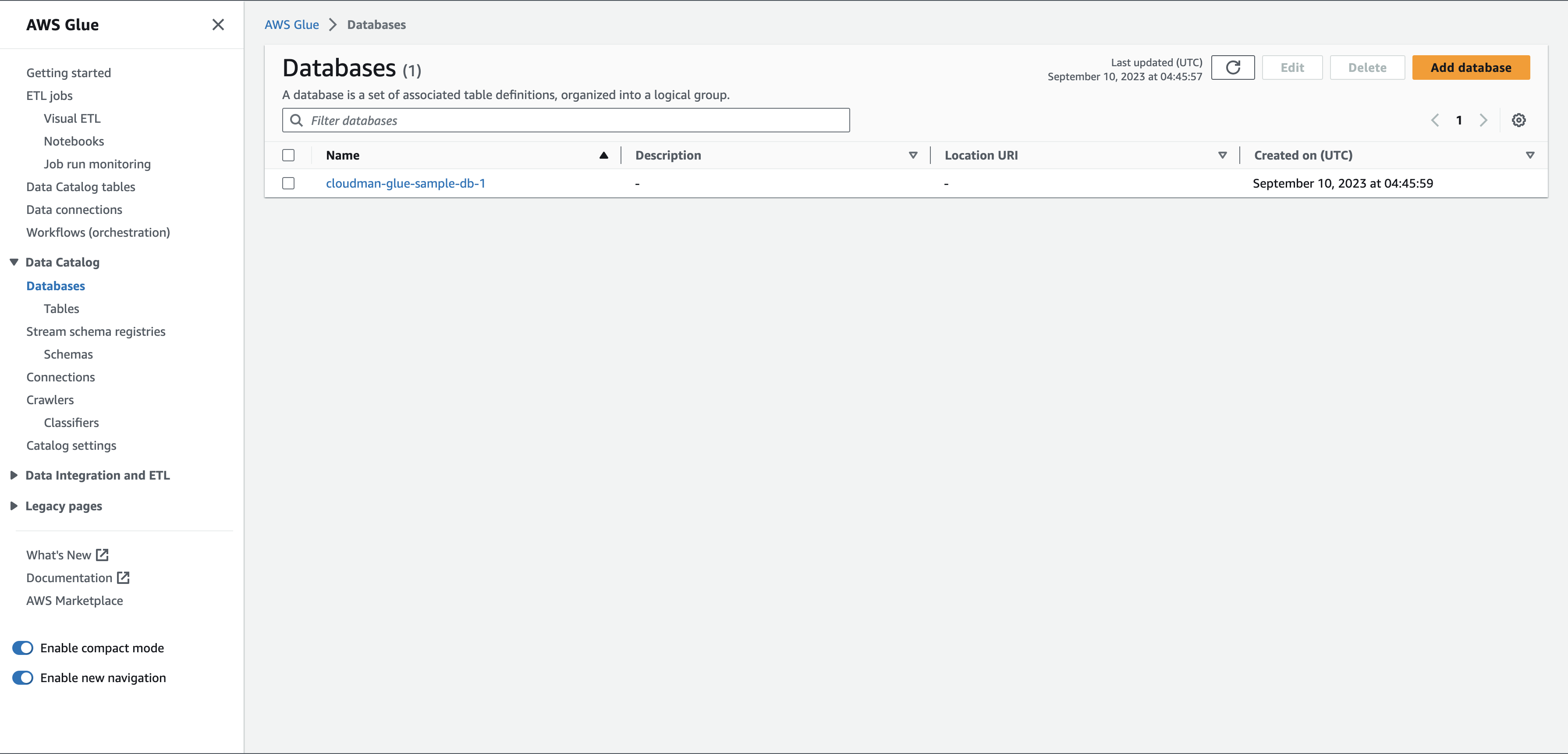
Glue DB 생성 완료 그리고 만들어진 DB를 클릭해봅시다. 그러면 이런 화면이 보이는데요, 오른쪽에 있는 Add table을 눌러봅니다.
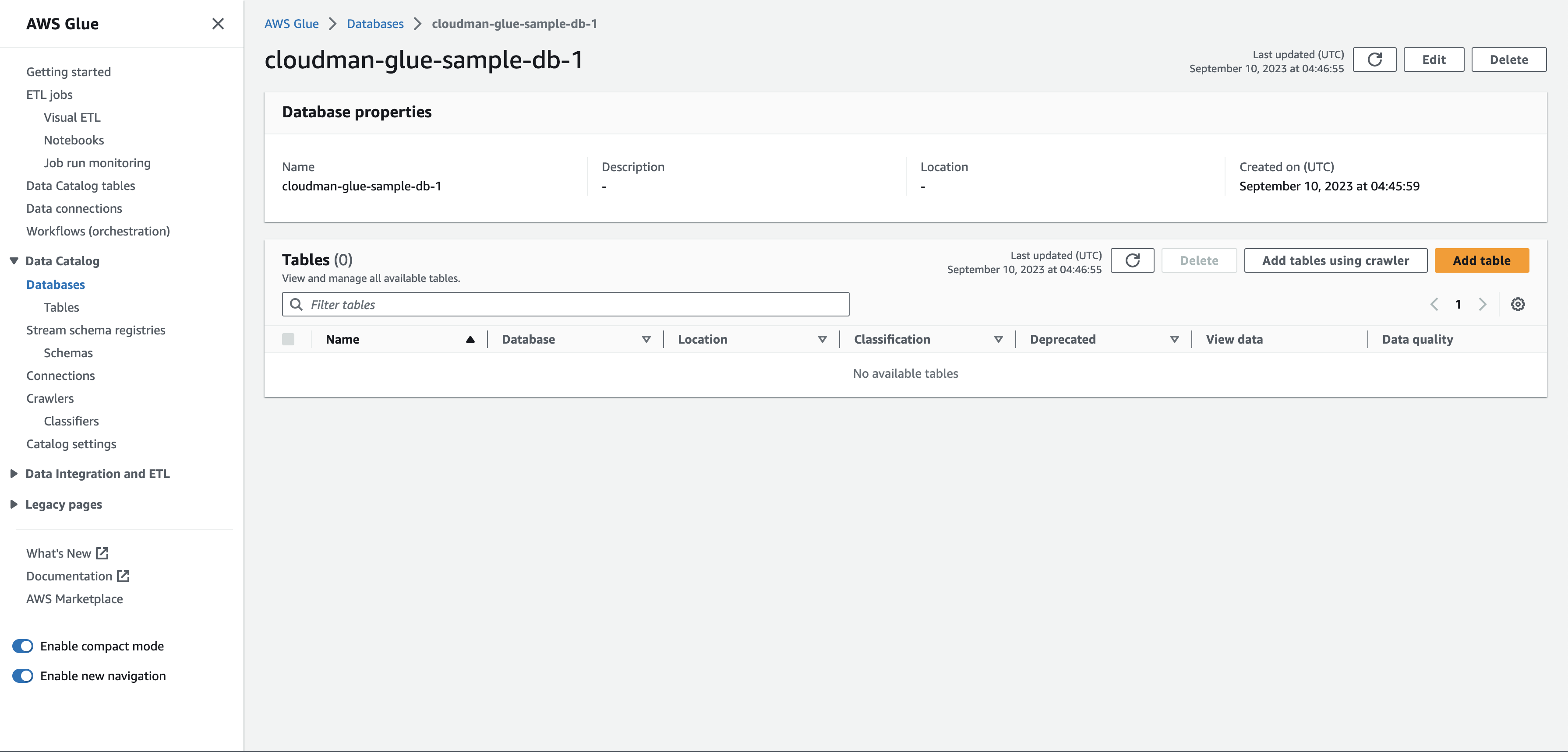
cloudman-glue-sample-db-1 메인화면 Add table을 누르면 아래처럼 table을 만들 수 있는 화면이 나오는데요.
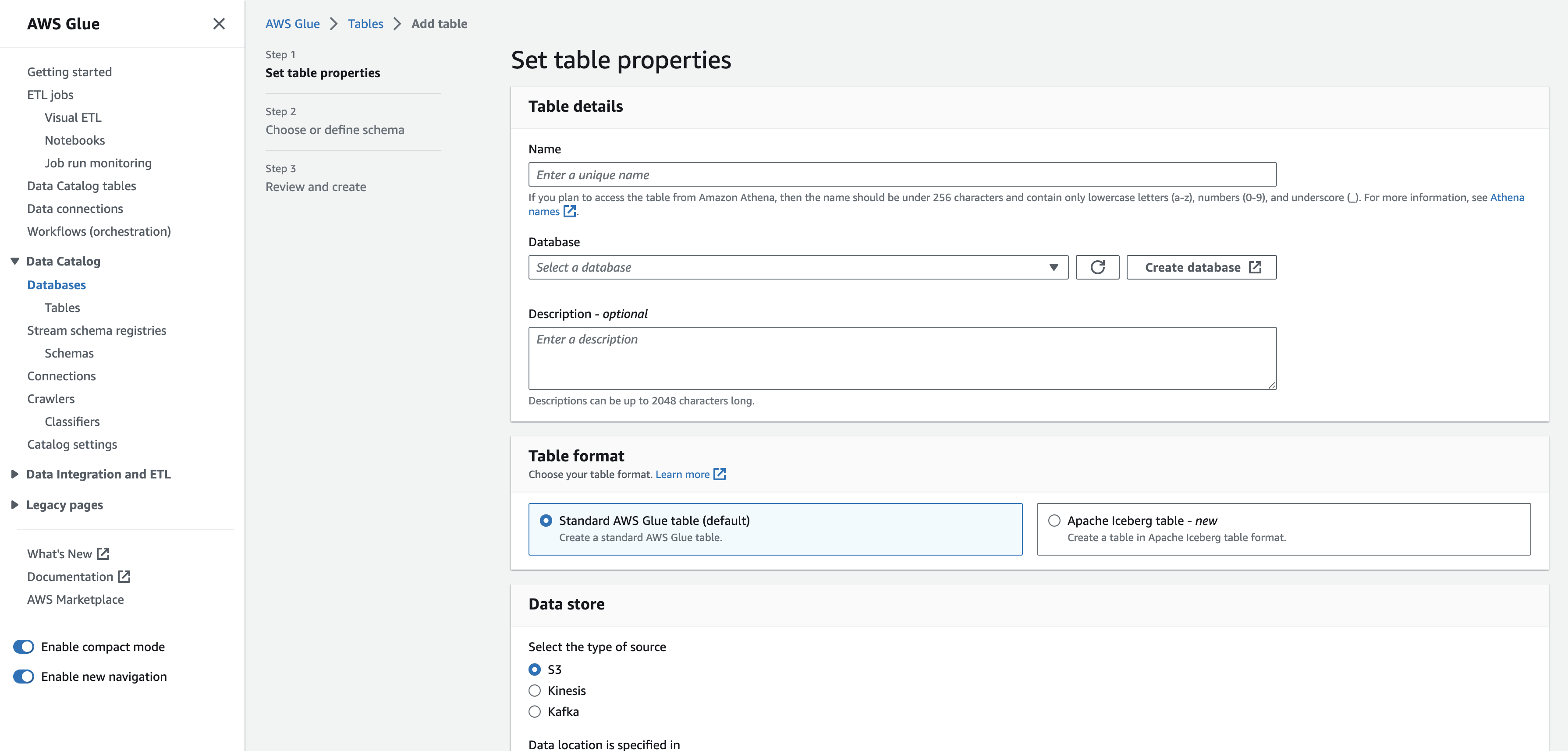
Step 1, 2, 3로 3가지 단계로 DB의 메타 데이터를 정의할 수 있습니다.
우선은 table의 properties를 정의할 수 있는 단계입니다.
해당 테이블의 이름과 어디에 원본 데이터가 저장되어 있는지 등을 선택할 수 있습니다.
우리는 여기서 아래처럼 설정할 겁니다.
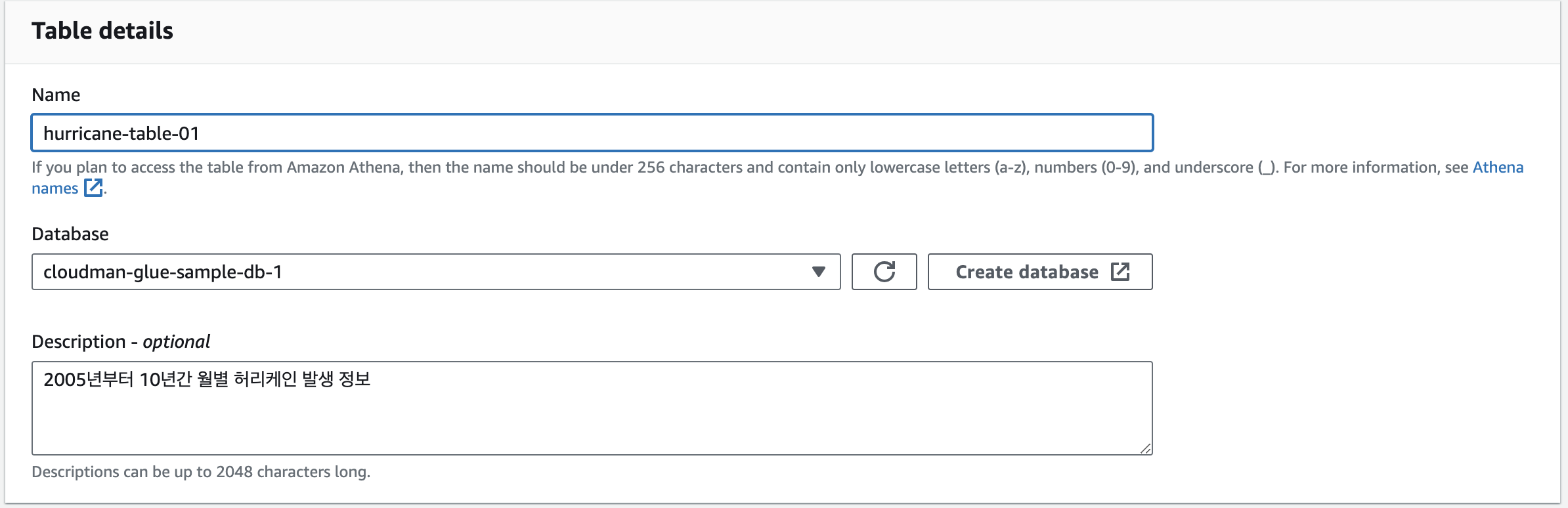
테이블 이름 및 테이블이 위치한 DB 설정 (아까 만든 cloudman-glue-sample-db-1로 설정) 
테이블 형식 (default인 Standard AWS Glue Table 선택) 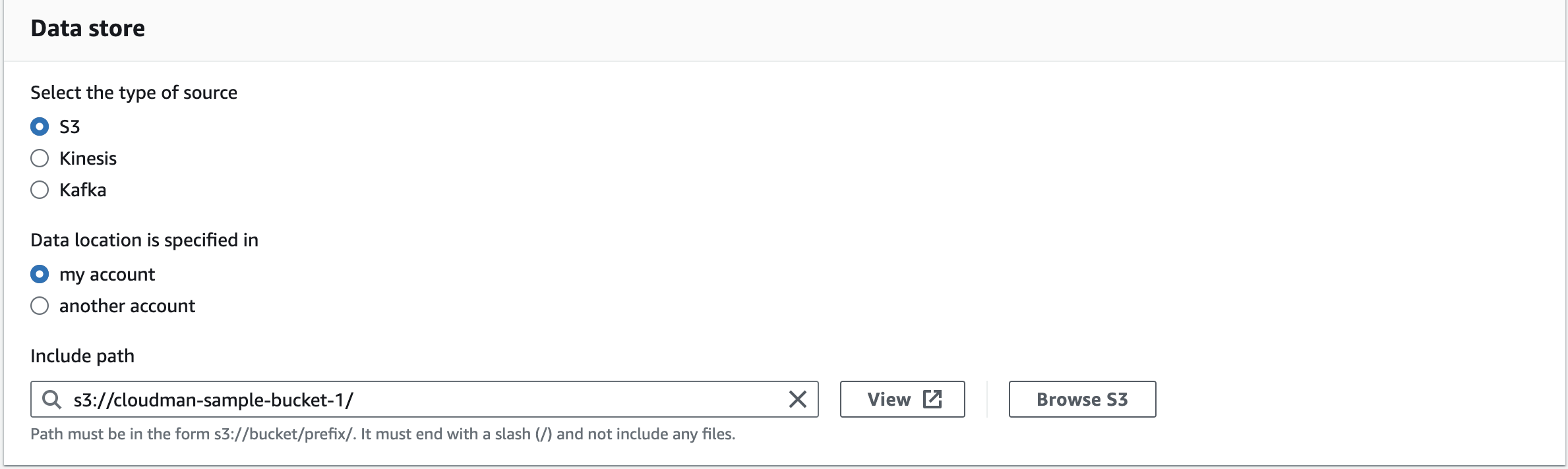
원천 데이터가 있는 위치 우선, 테이블 이름은 hurricane-table-1으로 정하고, table format은 default 세팅값으로 그대로 진행합니다.
그리고 우리가 허리케인 관련 파일을 저장했던 S3를 원천 데이터의 위치로 지정해줘야겠죠?
그래서 S3를 설정하고 내 계정에 있는 것이니까 my account, 마지막으로 S3 path를 입력해줍니다.
우리는 아까 S3에서 허리케인 정보 파일을 저장했던 cloudman-sample-bucket-1의 경로를 입력해줍니다.
(일반적인 경로의 naming rule은 s3://<내가 만든 버킷명>/<오브젝트 경로> 입니다)
그리고 경로 마지막에 / 를 넣어줘야 에러가 안 납니다.
S3 경로를 직접 입력해도 되고, 아니면 옆에 있는 Browse S3를 누르면
아래처럼 내 계정에 있는 모든 S3를 볼 수 있기 때문에 거기서 선택해도 됩니다.
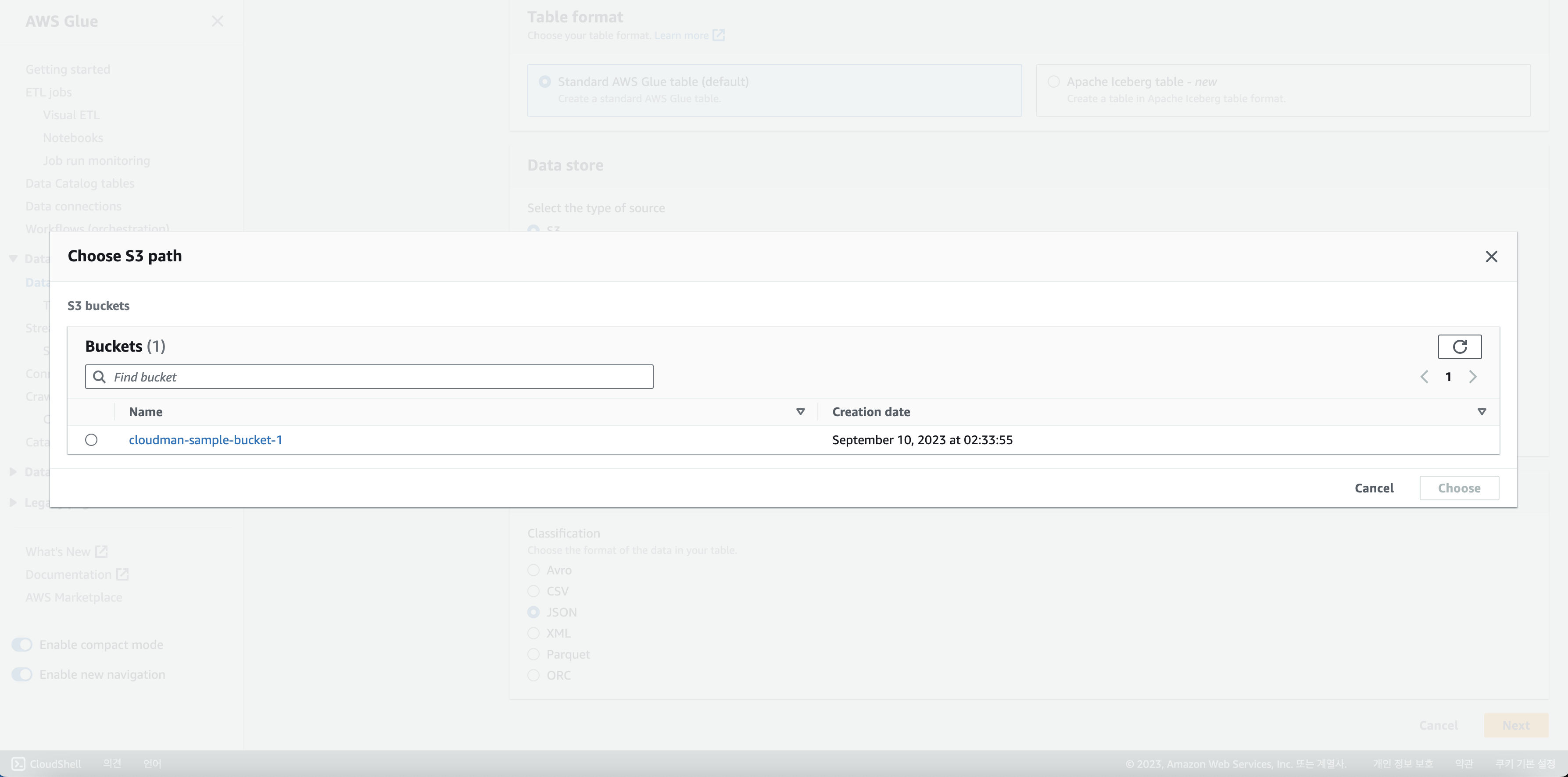
Browse S3 그러면 이제 선택을 하고 넘어가고 마지막으로 Data format을 선택하는데요.
우리는 스프레트시트 파일을 올렸으니 csv로 선택하겠습니다.
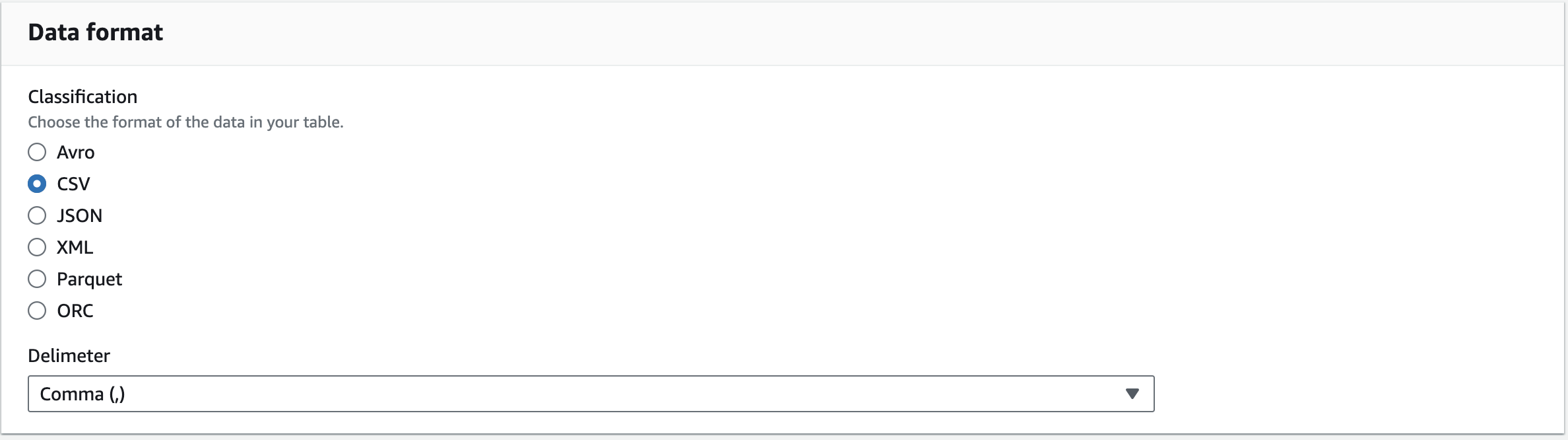
Data format 설정 그러면 이제 Next를 눌러서 다음 단계로 넘어가겠습니다.
(지금까지 이렇게 많이 했는데 이제 Step1 이었어???)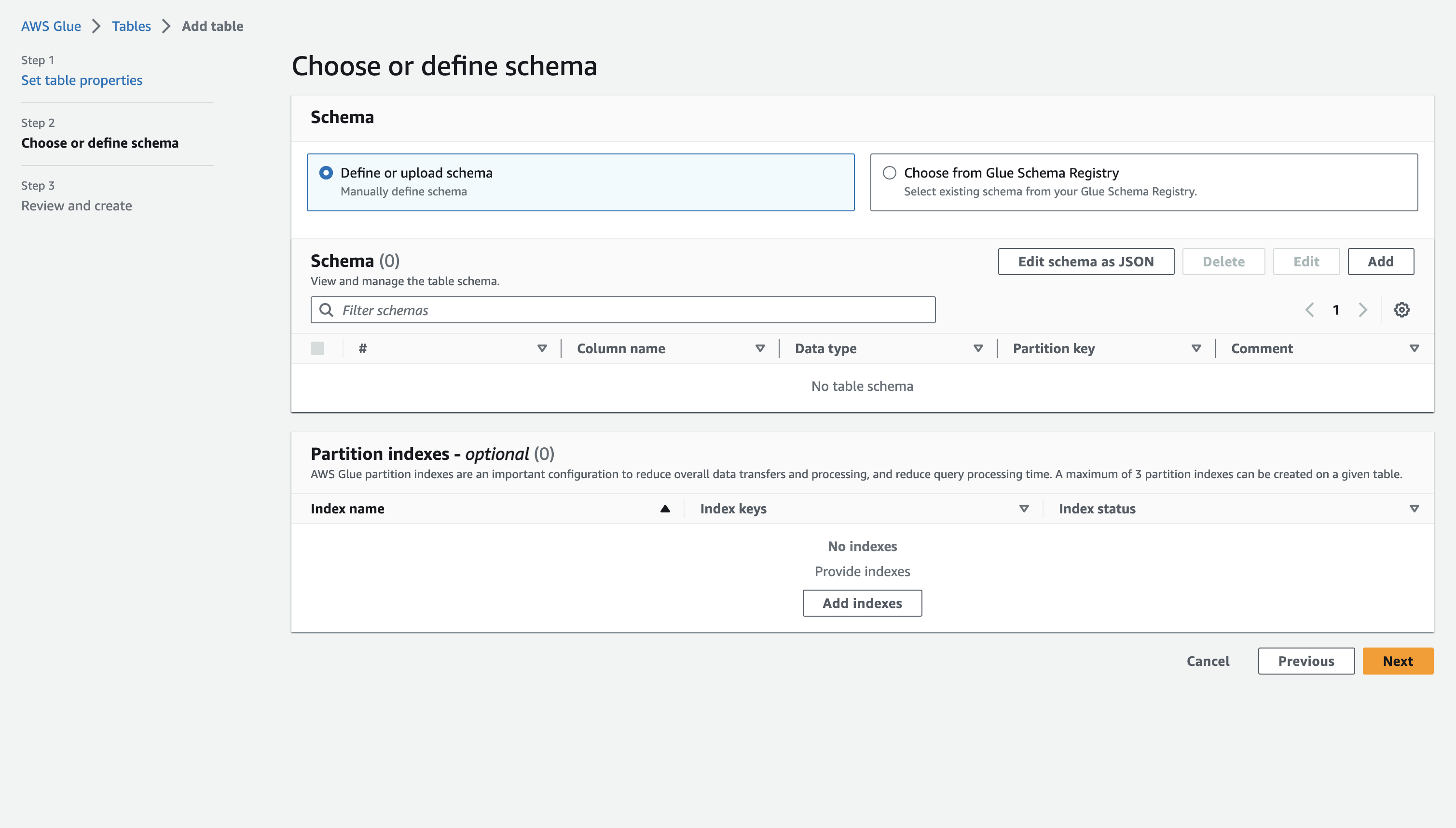
테이블 스키마 설정 여기서 이제 테이블이 어떤 column을 가지는지 정의해 볼 수 있는데요.
우리는 아까 column의 순서와 값을 알고 있기 때문에 그대로 정의해보겠습니다.
Add를 누르고 다음과 같은 화면이 나오면 차례대로 값을 입력합니다.
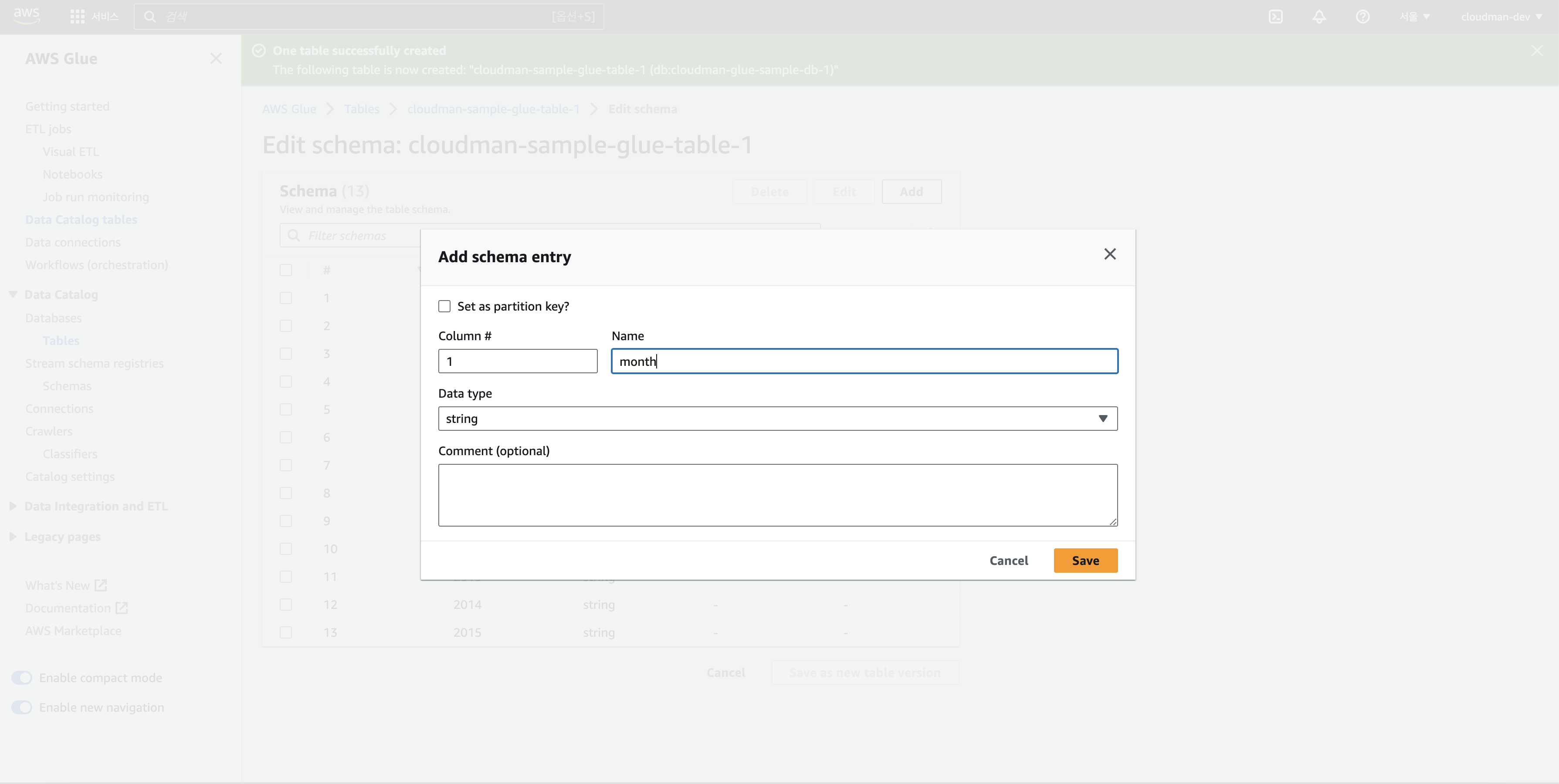
Add Schema 첫 번째 Column부터 차례대로 정의하면 우선 이름을 정하고 Data type을 정하면 됩니다.
우리가 보기에는 숫자라서 int나 float값을 선택해야 할 것 같지만
기본적으로 csv 파일의 값은 string으로 읽는다고 생각하시면 됩니다.
그래서 우리는 모든 데이터 타입을 string으로 하여 column을 정의해줍니다.
모두 정의하면 다음과 같은 화면이 보입니다.
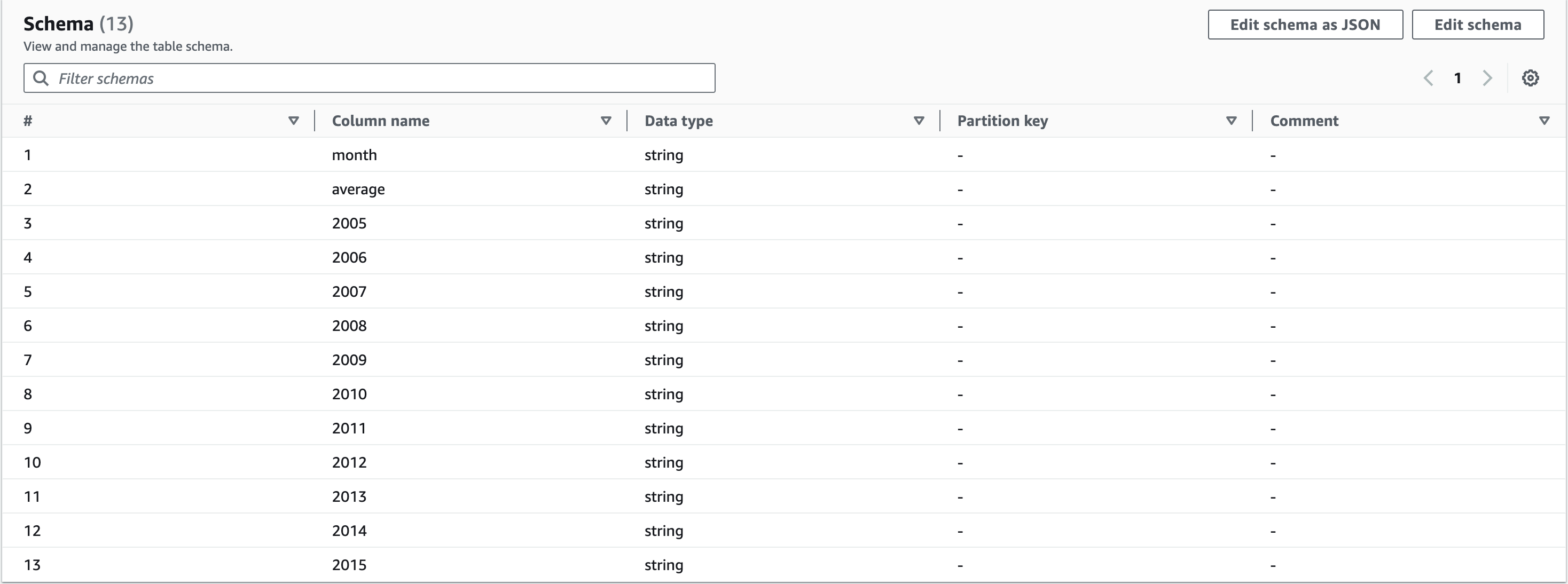
add버트으로 하나씩 추가해서 정의할 수도 있고
아래처럼 Edit schema as JSON으로 한꺼번에 전체 정보를 정의할 수도 있습니다.
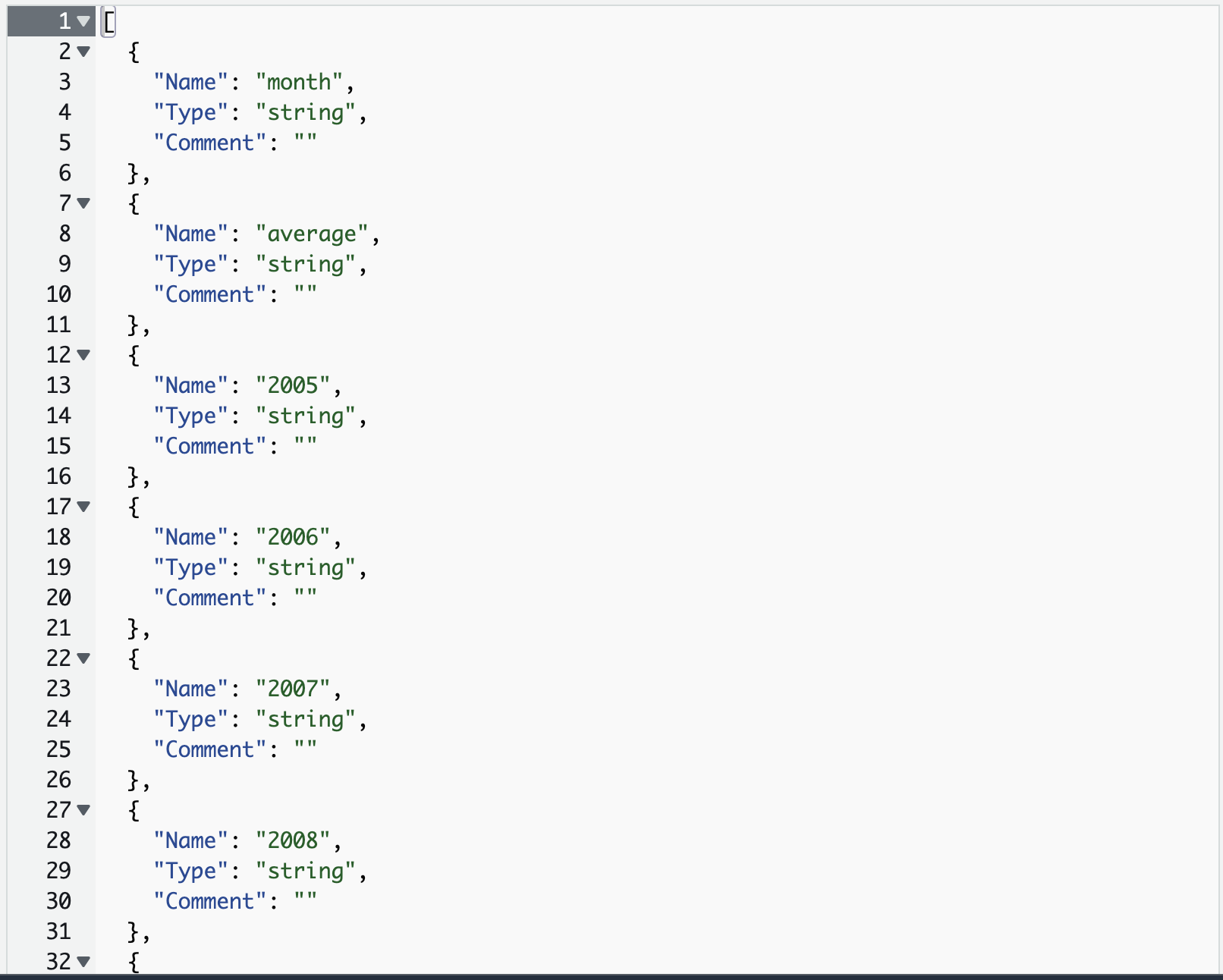
Edit 이제 Next를 눌러 다음으로 진행하고 바로 Create를 눌러 완료를 합니다.
(지금까지 노가다하시느라 수고하셨습니다ㅠ)그러면 이제 우리가 저장했던 파일은 마치 RDS에 저장한 파일처럼 query를 날려서 데이터를 읽고 수정하는 것이 가능합니다.
그럼 직접 Athena로 SELECT 쿼리를 날려서 해당 값을 잘 읽어오는지 확인해볼까요?
다음편인 AWS Athena에서 다뤄보도록 하겠습니다.
'Cloud 기초 > AWS 기초' 카테고리의 다른 글
AWS RDS 기초 (RDS MariaDB 생성) (0) 2023.09.10 AWS EC2 기초 (생성 및 접속까지) (0) 2023.09.06 AWS Athena 기초 (Athena SQL 작업) (0) 2023.09.06 AWS S3 기초 (버킷 생성 및 데이터 업로드) (0) 2023.09.06 AWS (아마존 클라우드 서비스) 소개 (0) 2023.09.06